SCIENTIFIC ARTICLES
Abstract
Diabetic nephropathy, hypertension, and glomerulonephritis are the most common causes of chronic kidney diseases (CKD). Since CKD of various origins may not become apparent until kidney function is significantly impaired, a differential diagnosis and an appropriate treatment are needed at the very early stages. Conventional biomarkers may not have sufficient separation capabilities, while a full-proteomic approach may be used for these purposes. In the current study, several machine learning algorithms were examined for the differential diagnosis of CKD of three origins.
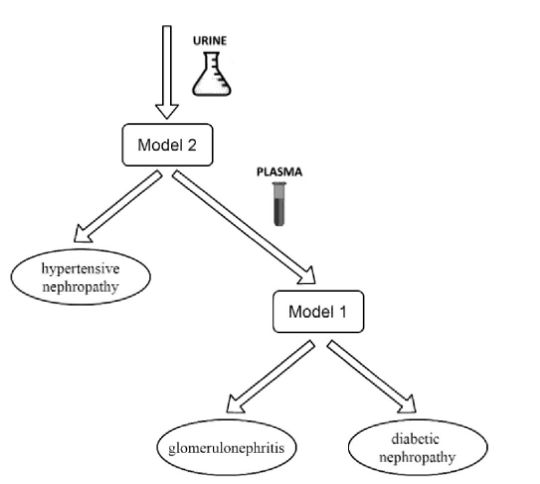
The tested dataset was based on whole proteomic data obtained after the mass spectrometric analysis of plasma and urine samples of 34 CKD patients and the use of label-free quantification approach. The k-nearest-neighbors algorithm showed the possibility of separation of a healthy group from renal patients in general by proteomics data of plasma with high confidence (97.8%). This algorithm has also be proven to be the best of the three tested for distinguishing the groups of patients with diabetic nephropathy and glomerulonephritis according to proteomics data of plasma (96.3% of correct decisions). The group of hypertensive nephropathy could not be reliably separated according to plasma data, whereas analysis of entire proteomics data of urine did not allow differentiating the three diseases.
Nevertheless, the group of hypertensive nephropathy was reliably separated from all other renal patients using the k-nearest-neighbors classifier “one against all” with 100% of accuracy by urine proteome data.
